
 日本語
日本語 Vietnamese
VietnameseRedis and Redis Stack

Introduction
Redis (Remote Dictionary Server) is one of the NoSQL-style database management systems.
Used to store structured data as key-value on RAM with high performance.
Can be used as a database, cache or message broker. Redis can also be used as a database stored in RAM to speed up processing.
Redis currently offers response times at speeds of less than a millisecond, as Redis allows you to store on your RAM faster than when storing on hard drives, about 150,000 times faster than hdd access and 500 times faster than SSD access.
Good use in linking microservices together.
Features of Redis
Data model
Redis has no tables. Redis stores data as a key-value.
Redis data types used to store value:
STRING: Can be string, integer, or float. Redis can work with both strings, individual parts of the string, as well as increase/ decrease the value of the integer, float.
LIST: The associated list of strings. Redis supports push, pop operations from both sides of the list, trim based on offset, read 1 or more items of the list, search and delete values.
SET: Set of strings (not sorted). Redis supports operations that add, read, delete each element, check the appearance of the element in the set. Redis also supports set operations, including intersect/union/difference.
HASH: Stores hash tables of key-value pairs, in which keys are randomly sorted, in no order at all. Redis supports operations to add, read, delete each element individually, as well as read all values.
ZSET (sorted set): Is a list, in which each element is a map of 1 string (member) and 1 floating-point number (score), the list is sorted by this score. Redis supports adding, reading, deleting each element, taking out elements based on the range of the score or string.
Replication – Persistence:
Redis uses a primary-replica architecture and supports asynchronous replication, data can be copied to many different servers. This makes for improved read performance (as requests can be split between servers) and faster recovery when the main server experiences an outage. For maintenance, Redis supports point-in-time backups (copying Redis data to disk).
In-Memory Data Store
Redis stores data on RAM, so reading and writing data is much faster than on a hard drive.
But also because all the data on RAM will be lost when turning off server, However, one solution was to use Redis Persistence.
Persistent redis
Although working with key-value data stored on RAM, Redis still needs to store data on the hard drive to ensure data integrity when something goes wrong (the server is powered off) as well as recreate the dataset when restarting the server. Redis provides 2 main methods for backing up data to hard drives, namely RDB and AOF.
RDB (Redis Database)
RDB creates and backs up a snapshot of the DB to the hard drive every certain period of time.
Advantages of RDB
RDB allows users to save different versions of the DB, which is very convenient when something goes wrong.
RDB helps optimize Redis performance. The main Redis process will only do the work on RAM, including the basic operations required from the client side such as add/read/delete, while a child process will take care of disk I/O operations. . This organization helps maximize Redis performance.
Disadvantages of RDB
Usually users will set up to create RDB snapshot every 5 minutes (or more). Therefore, in the event of a problem, Redis cannot operate, data in the last minutes will be lost.
RDB needs to use fork to create child processes for disk I/O operations. In case the data is too large, the fork process can be time consuming and the server will not be able to respond to the request from the client for several milliseconds or even 1 second depending on the amount of data and CPU performance.
AOF (Append Only File)
AOF saves all write operations received by the server, these operations will be rerun when restarting the server or resetting the original dataset.
Advantages of AOF
AOF Redis ensures that the dataset is more stable. Users can configure Redis to log once a second or every query.
Redis logs AOF in an append-to-end of an existing file, so a seek process on an existing file is unnecessary. Even if the log ends with a half-written command for some reason (disk is full or other reasons), the redis-check-aof tool can still fix it easily.
Redis provides a background process, allowing to record AOF files when the file size is too large. The rewrite is completely safe because while Redis continues to add to the old file, a completely new file is created with the minimal set of operations required to create the current dataset, and when this second file is ready, Redis transfers two files and starts adding a new file.
Disadvantages of AOF
AOF files are often larger than equivalent RDB files for the same data set.
AOF may be slower than RDB depending on fsync policy. Generally with fsync set to second, performance is still very high, and with fsync disabled it will be exactly as fast as RDB. RDB can still provide more guarantees about maximum latency even in case of very large write load.
Performance
Compared to a traditional on-disk database in which most tasks require repeated access to the drive, Redis only needs to get the calculated result. Therefore, Redis performance is remarkably fast for conventional read or write tasks along with low latency and high throughput.
Supports more operations and 10x faster response times. The average read and write operations take less than a millisecond and support millions of operations per second.
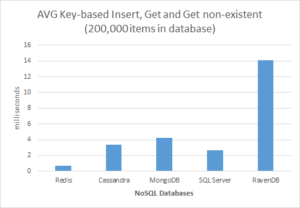
Common use cases of Redis
Caching
Save the pending task list
Game leaderboards
Session archive
Machine Learning
Real-time analytics
…
Redis Stack
The Redis Stack was created to enable developers to build real-time applications with a backend data platform that can reliably handle requests in milliseconds by extending Redis with data models and data processing tools.
Redis Stack has 5 module packages: RedisJSON, RediSearch, RedisGraph, RedisTimeSeries and RedisBloom.
In addition, the Redis Stack also includes RedisInsight, a visualization tool for understanding and optimizing data.
RedisInsight interface
To easily understand how the Redis Stack works, we will start to learn how to use 2 modules RedisJSON and RediSearch with the node-redis library.
Install node-redis library
npm install redis
Connect to Redis Server
import { createClient } from 'redis';
const client = createClient({
url: 'redis[s]://[[username][:password]@][host][:port][/db-number]'
});
client.on('error', (err) => console.log('Redis Client Error', err));
await client.connect();
RedisJSON
RedisJSON is a Redis module that provides JSON support in Redis. RedisJSON allows you to store, update, and retrieve JSON values in Redis just like you would with any other Redis data type. RedisJSON also works simultaneously with RediSearch to allow you to index and query your JSON documents.
The document is stored as binary data in a tree structure, which allows quick access to child elements.
Storing JSON Documents in Redis
The JSON.SET command stores a JSON value at a given JSON Path in a Redis key.
Here, we’ll store a JSON document in the root of the Redis key “users“:
await client.json.set(‘noderedis:users’, ‘$’, {
name: 'Alice', age: 29 });
Retrieving JSON Documents from Redis
const results = await client.json.get('noderedis:users');
results will contain the following:
{ name: 'Alice', age: 29 }
RediSearch
RediSearch is a Redis module that provides query, sub-indexing, and search capabilities for Redis. To use RediSearch, you first declare indexes on your Redis data. You can then use the RediSearch query language to query that data.
RediSearch uses compressed, inverted indexes to index quickly with low memory capacity.
RediSearch provides accurate phrase comparison, fuzzy search (search for “approximation”), numeric filtering,…
Indexing and Querying Data in Redis Hashes
Creating an Index
Before we can perform any searches, we need to tell RediSearch how to index our data, and which Redis keys to find that data in. The FT.CREATE command creates a RediSearch index. Here’s how to use it to create an index we’ll call idx:animals where we want to index hashes containing name, species and age fields, and whose key names in Redis begin with the prefix noderedis:animals:
await client.ft.create('idx:animals', {
name: {
type: SchemaFieldTypes.TEXT,
sortable: true
},
species: SchemaFieldTypes.TAG,
age: SchemaFieldTypes.NUMERIC
}, {
ON: 'HASH',
PREFIX: 'noderedis:animals'
}
);
Once we’ve created an index, and added some data to Redis hashes whose keys begin with the prefix noderedis:animals
Add a document
Use the HSET command to create a new hash document and add it to the index:
await client.hSet('noderedis:animals:1', {name: 'Fluffy', species: 'cat', age: 3});
await client.hSet('noderedis:animals:2', {name: 'Ginger', species: 'dog', age: 4});
Querying the Index
To search the index for documents containing specific words, use FT. SEARCH
const results = await client.ft.search(
'idx:animals',
'@species:{dog}',
{
SORTBY: {
BY: 'age',
DIRECTION: 'DESC' // or 'ASC' (default if DIRECTION is not present)
}
}
);
results will look like this:
{ total: 1, documents: [ { id: 'noderedis:animals:2', value: { name: 'Ginger', species: 'dog', age: '4' } } ] }
Indexing and Querying Data with RedisJSON
Creating an Index
To create an index for a JSON document
await client.ft.create('idx:users', {
'$.name': {
type: SchemaFieldTypes.TEXT,
SORTABLE: 'UNF'
},
'$.age': {
type: SchemaFieldTypes.NUMERIC,
AS: 'age'
},
}, {
ON: 'JSON',
PREFIX: 'noderedis:users'
});
Querying the Index
We will use the FT.SEARCH command and RediSearch query language. For example, a query to find users under the age of 30:
const results = await client.ft.search('idx:users', '@age:[0 30]');
results data returned:
{
"total": 1,
"documents": [
{
"id": "noderedis:users",
"value": {
"name": "Alice",
"age": 29
}
}
]
}
Conclusion
Redis is an open source software package with many advantages, so it is widely used in the software development process.
It’s super fast, easy to set up and use, and supports flexible data structures. Redis is a great choice when it comes to caching data or applications with real-time requirements.
With the same mechanism of storing data on RAM, compared to Memcached , Redis supports more data types and more operations on the server side. There is also a default mechanism to back up data to disk while Memcached does not have this mechanism. So if you want your system to be cacheable but with complex data structures, then Redis will be a better choice.
References
https://byterot.blogspot.com/2012/11/nosql-benchmark-redis-mongodb-ravendb-cassandra-sqlserver